Role: Design Technologist · UX Engineer
Date: 2025
Company: Personal Project
Role: Design Technologist · UX Engineer
Date: 2025
Company: Personal Project

Designed and built an end-to-end pipeline that transforms design tokens from Figma into structured, theme-aware outputs for web applications. Includes a custom TypeScript engine for normalization, alias resolution, and multi-theme transformation, bridging design systems and frontend implementation.
Focus: Designed and built an end-to-end token pipeline that normalizes Figma variables into W3C-compliant tokens, resolves aliases, extracts themes, and outputs production-ready CSS/JSON/SCSS.
System Architecture: Built as a zero-dependency TypeScript engine (@startoken/engine) shared across web app, Figma plugin, and future CLI via monorepo strategy.
Design tokens define the visual contract between design and engineering, yet in practice, most teams treat them as static files rather than structured data. Figma variables use a proprietary format that doesn't map to production code. Naming conventions diverge across teams. Manual handoff introduces drift between what designers intend and what engineers implement. As systems scale beyond a single product, this gap becomes a structural bottleneck: inconsistent outputs, duplicated effort, and no reliable source of truth across surfaces.
The core issue isn't a lack of tokens, it's a lack of infrastructure to manage them. Auditing multiple design system workflows revealed four systemic failures:
Rather than building another token editor, I designed a token pipeline, a system that separates concerns into discrete, testable stages. The core idea: treat tokens as structured data flowing through a deterministic transformation process, where each stage has a single responsibility and predictable output.
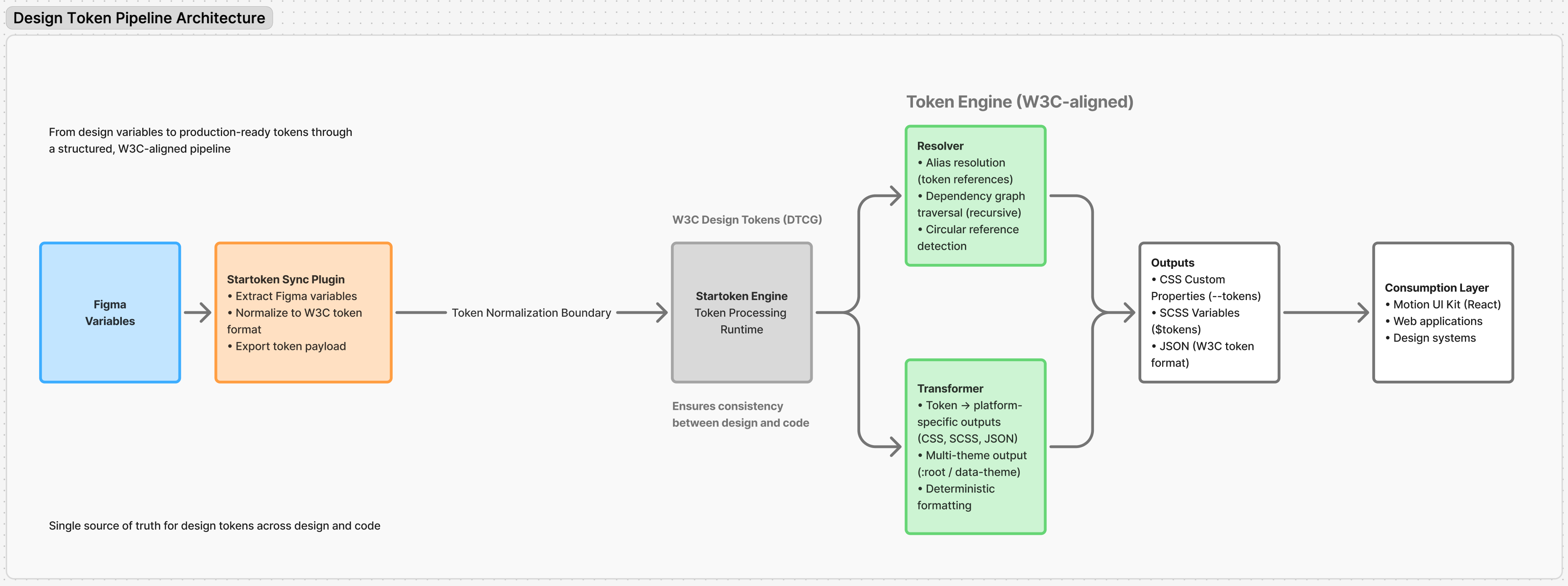
The pipeline is a sequence of typed stages. Each stage receives structured input, performs one transformation, and passes typed output forward. No stage knows about any other. This constraint makes the system testable at each boundary and allows stages to be replaced or extended without side effects.
Figma → Plugin → Normalizer → Resolver → Transformer → UI Preview → Output
Decision: Adopt W3C DTCG as the canonical token format instead of a custom schema. Trade-off: DTCG is still a draft spec — some edge cases (composite tokens, multi-value types) lack full definition. Adopting early means committing to a moving target. Outcome: Vendor-neutral interoperability. Tokens produced by Startoken can be consumed by Style Dictionary, Figma Tokens, or any DTCG-compliant tool without adapters. Standardizing early avoids migration debt when the spec stabilizes.
Decision: Build a purpose-built TypeScript engine rather than extending Style Dictionary or Theo. Trade-off: Higher upfront effort. No community plugin ecosystem. Full ownership of maintenance and edge case handling. Outcome: Complete control over the normalization → resolution → transformation flow. Style Dictionary assumes tokens are already well-structured; Startoken handles the messy reality of raw Figma exports. The engine runs identically in browser, Node, and Figma sandbox — something no existing tool supports natively.
Tokens frequently reference other tokens in chains: color.primary → brand.blue.500 → palette.blue → #2563EB. The Resolver builds a directed dependency graph of all token references, then walks each chain to its terminal value. During traversal, it tracks visited nodes — if a token appears twice in the same chain, that's a cycle, and the resolver throws a descriptive error instead of entering an infinite loop. The output is a flat map where every token holds its fully resolved concrete value. This guarantees that downstream transformers never encounter unresolved references.
Client-side processing: All token resolution happens in the browser. This enables instant preview and zero-backend deployment, but limits throughput for very large token sets (1,000+). The resolver is O(n·d) where n = token count and d = average alias depth — acceptable for most design systems, but a bottleneck at extreme scale. Single-pass normalization: The normalizer assumes Figma's current variable export format. If Figma changes their API structure, the normalizer breaks. This is isolated by design — only one stage needs updating. No runtime validation: The pipeline trusts that input conforms to expected shapes after normalization. Adding JSON Schema validation at stage boundaries would improve robustness but add processing overhead.
The engine detects theme-scoped tokens (light/dark/brand variants) and generates separate output sets per theme. Themes map to data attributes at runtime — [data-theme="dark"] scopes CSS custom properties without specificity conflicts or token duplication. This separation happens at the token level, not the CSS level, so each theme output is a complete, self-contained token set.
Monorepo Strategy: @startoken/engine is the shared core — a zero-dependency TypeScript module that runs in Node, browser, or Figma sandbox. The monorepo strategy ensures this single engine is consumed by the web app, Figma plugin, and future API/CLI clients, preventing logic duplication across surfaces.
Each decision below includes the rationale, the trade-off accepted, and the resulting outcome:
Decision: No external runtime dependencies in the core engine. Trade-off: Reimplemented utilities that libraries like lodash provide (deep merge, path traversal). More code to maintain. Outcome: The engine runs in any JavaScript environment — browser, Node, Figma plugin sandbox — without polyfills, bundler configuration, or environment detection. Deployment surface is unlimited.
Decision: All token processing happens in the browser, not a server. Trade-off: No persistent storage between sessions. Limited by browser memory for extremely large token sets. Can't trigger CI/CD pipelines directly. Outcome: Zero infrastructure cost. Instant preview without network latency. Users see token transformations in real-time as they modify inputs. The engine can later be deployed server-side without code changes — it's environment-agnostic by design.
Decision: Treat Figma-to-DTCG conversion as an explicit, isolated pipeline stage rather than inline preprocessing. Trade-off: Adds a processing step and requires maintaining a mapping layer that tracks Figma's export format. Outcome: Clean separation between "Figma's world" and "the token system." If Figma changes their variable export structure, only the normalizer needs updating — the resolver and transformer are unaffected. Also enables non-Figma inputs (JSON files, API responses) to enter the pipeline at the same boundary.
Decision: Extract themes (light/dark/brand) during token resolution, producing separate token sets per theme — not at the CSS output level. Trade-off: Increases the number of output artifacts (one file per theme per format). Requires consumers to load the correct theme set. Outcome: Each theme output is a complete, self-contained token set. No CSS specificity conflicts between themes. Runtime switching uses data attributes ([data-theme="dark"]) scoping CSS custom properties. Themes can be loaded on demand, reducing initial payload.
The pipeline processes tokens through six stages. Each stage receives typed input from the previous stage and produces typed output for the next. The UI reflects pipeline state in real-time with debounced updates — changes propagate through all stages without blocking interaction.
Figma variables are extracted via plugin → the Normalizer converts Figma's proprietary collection/mode structure into valid DTCG JSON → the Resolver walks alias chains and flattens all references to concrete values → the Transformer generates target formats (CSS custom properties, SCSS variables, JSON) → the Preview renders output as live CSS applied to sample components → the user exports final artifacts. Each boundary is typed — if a stage produces malformed output, the next stage fails explicitly rather than propagating bad data.

The plugin reads Figma's variable collections, modes, and alias references, then serializes them as structured JSON. This raw export preserves Figma's hierarchy (collections → modes → variables) without interpretation — normalization happens in the next stage, keeping the plugin thin and focused on data extraction.

Resolved tokens are applied to a component sandbox as CSS custom properties in real-time. The preview uses requestAnimationFrame-throttled updates to reflect pipeline changes without layout thrashing. Users see exactly what the generated tokens look like when applied to real UI elements — buttons, cards, typography — before exporting.

A supporting capability that validates token names against the DTCG schema structure. Teams test their naming conventions (category.property.variant.state) before committing to a structure, catching naming inconsistencies at authoring time rather than after tokens propagate through the system.
Measured and observed outcomes from building, testing, and demonstrating the pipeline:
Design systems are maturing, but the tooling between Figma and production code has not kept pace. Most teams rely on manual processes or loosely connected plugins that produce inconsistent results. The gap is structural: Figma speaks one language (collections, modes, local variables), code speaks another (CSS properties, SCSS maps, JSON dictionaries), and there is no reliable translation layer between them.
Token pipelines solve this by treating the translation as a first-class engineering problem, not a design task, not a manual handoff step, but a deterministic system with typed stages, alias resolution, theme extraction, and multi-format output. Startoken is a working implementation of this idea: a pipeline that takes raw Figma variables and produces production-ready tokens without manual intervention. This is the infrastructure that modern design systems need but rarely build.
Planned enhancements to extend the system: